In this development diary, I provide an update on progress made on Koto in the month of June 2021!In Dev Diary 9, I highlighted the following goals for Koto development over various development sessions for the June.
Settle on a model I am satisfied with for multi Koto Libraries and implement it. All of it.
Implement per-Playlist settings such as randomization and model (moving that out of the database too).
Implement a Solarized built-in theme, since that is a fairly popular stylistic choice. I would love to hear your ideas on additional themes too, even silly / fun ones!
June has been an incredibly busy month, not just for Koto development but various efforts in Solus. So as a result, unfortunately I was not able to get to all the tasks I was hoping for. For example, we have had a massive toolchain upgrade related to glibc and gcc, alongside various preparation work for an upcoming release. This has taken up a considerable amount of time that would otherwise be myself sitting down and focusing on Koto development for long stretches of time.Expanding on this, refactoring all the library related code and getting multi-Library supported implemented took longer than I expected. However aside from some odd inconsistencies with GLib and multi-threading, I am pretty happy with the work I have done to implement support for multiple Libraries and begin the preparation work for audiobook functionality.For starters, the first thing I did was implement our HashTable in our Cartographer for libraries, allowing us to assign the UUID of the library (generated during library creation time) to a pointer of the KotoLibrary struct, which has various relevant details for it. This enable us to reference it throughout the codebase via several different functions, such as:
koto_cartographer_get_library_by_uuid
koto_cartographer_get_library_containing_path
koto_cartographer_get_libraries_for_storage_uuid
koto_cartographer_get_libraries
While doing this, I cleaned up the Cartographer code to be more in line with other classes we have, the various macros defined, and type checking we use in each function. Alongside this initial work, I had implemented a function in our KotoAlbum called koto_album_get_uuid, which returns a pointer to the KotoAlbum's UUID, which is consistent with other classes / structs we have like Artist, Playlist, and Track. This function gets used for sanity checking in Cartographer, so when we add an Album we actually make sure we don't add it when it already exists. It is additionally used in some of our Artist code and file indexer.Once this was done, I separated out our functions responsible for reading from our database tables, moving it to reside in the same section of our codebase as Cartographer and our database helper functions. This helped clean up the library code so it would not be so unwieldy to refactor, cleanup, and mentally parse.For several weeks after that, I was hard at work on our new multi-Library functionality. In Dev Diary 9, I mentioned that was still working on determining the best model for implementing indexing and organizing content across libraries. I am fairly happy with the current implementation, though there is always room for improvement, so time to detail the direction I opted to take.The biggest changes to our folder and file indexing was the refactoring of the file indexing logic into a dedicated file indexing function. While this may not sound exciting, it is worth noting that this functionality was previously specific to Koto Albums. Obviously this poses a problem for content which have no albums and in scenarios where we may have music directly within a specific folder that we may associated with an artist, but in reality can by any arbitrary content, e.g. royalty free holiday music in specific folders that would otherwise be treated as artists. In scenarios where we have multiple CDs within an album, this code was added as another "depth" checking in our folder indexing function, whereas previously it was also in the Album.To aid in simplifying the logic for our file indexing as well as track sorting, I implemented several functions:
koto_track_helpers_get_name_for_file: This function takes in the full path to the file as well as an optional name of an artist. We will attempt to get the ID3 information for the file and if successful, return the "title" tag provided by the metadata assuming it is a correct string. If it is not a valid string or we failed to get ID3 information, we use our previous file indexing logic we had in the album to clean up the file name, including removing the name of the artist, hyphens, extra spaces, etc.
koto_track_helpers_get_position_based_on_file_name: This function will attempt to get the position of the track based on its file name. This existed previously as a "koto util" but was moved to a more sensible location for consistency.
Multiple sorting functions such as koto_track_helpers_sort_tracks_by_uuid aid in reducing duplicate track sorter code. This sorting logic saw substantial cleanup, type checking, and simplification as well, so I am in a much happier place with how we perform sorting, and it is done in a manner that is consistent across the application.
Of course, all of these helpers would not actually be all that helpful if we already had the file to begin with, for example we have multiple libraries (maybe even detachable storage devices) with overlapping content. So to reduce the likelihood of there being duplicate tracks (not a guarantee but we try our best), we will create a "uniqueish key" that consists of the concatenation (fancy word for combining) of the name of the artist, album, and file name. In the case of no album, it is just the artist and file name. It is still technically feasible to have collisions, so this will likely need to be fleshed out more, but I thought it was a good middle-ground to being easy enough to generate given the metadata we would have at our disposal and the scenarios that would be required to get that sort of collision to occur. Anyways, if we happen to already have a reference to a KotoTrack loaded in our database and thus into Cartographer with that "uniqueish key", we instead reference that and leverage our multi-path logic to set the path to the file for that track. Otherwise, we create a new Track.That multi-path logic is completely new and was created to ensure we are able to store the relative path to a file for each Library, for each Artist, Album, and Track individually. It is important for me to emphasize the relative path aspect of it, as what that will allow is for a much more seamless library migration and support process in the event you do something as simple as changing the mount point of your chonker hard-drive containing those forty million live versions of all your favorite artists. If we were storing the absolute path, we would have to change the database entry for every single Artist, Album, and Track that were stored in that library. When we use a relative path, we do not need to change a single one.The flexibility introduced in having multi-path support for each of our primary content / organization types (excluding Playlists, which are not literally on your "disk") allows users to get really granular on where they store specific types of content for specific types of Libraries. Want your podcasts on a completely different drive or location on that drive? No problem. Want to have your Music be an amalgamation of several Libraries across your XDG_MUSIC_DIR, another Library at a different mount point, and yet another on a removal storage? Also not a problem.Each of the paths for our Artists, Albums, and Tracks are stored in dedicated tables with a reference to the UUID of that specific content type, with a collation of the metadata being stored in the respective artists, albums, and tracks tables. This reduces the overall size of our database by not storing metadata per each path, and simplifies any logic that would be required for mounting, dismounting, or indexing Libraries on the fly. These paths get loaded in and we will iterate through them as part of our dedicated "get_path" functions that we have on the various structs, like koto_track_get_path. At the moment, this will just iterate through each Library that the content is in and return the first hit, however the goal in the future is to:
Prioritize local storage, even going so far as prioritizing local NVMe storage over HDDs when possible.
Leverage our availability check to ignore any Libraries which are not currently available. This is especially useful for removable media devices.
At the moment, we have logic in place to monitor the related Volume for a Library to be notified when it becomes unmounted, and subsequently send out a signal in our application, however I have yet to implement the UX elements for indicating when that content is not available, nor a global VolumeMonitor to notify when it becomes available again. I expect to start working on this once I start implementing Device Synchronization, as it does not make that much sense to do it before, there simply are higher priority items to be worked on.Since the indexing of content within a sub-directory of a Library's folder without the requirement of an album is now possible, such as an artist for music or the name of a podcast, we needed a way to display that content. After some discussion with folks on my Twitch stream, I opted to go the route of refactoring the track table used in the Playlist pages into a new component called TrackTable (I know, so creative). This made perfect sense given you may very likely be storing an assortment of music from various artists and albums within that folder, like if it is a list of "streaming approved" copyright free music that would not make sense to individually separate into artist-specific folders. The table used for the Playlist pages already assumed this, so extending that to the Artist view seemed logical.This is made even more useful given we actually keep track of all KotoTracks within a KotoArtist in addition to any Albums. This is then leveraged as part of a new signal we emit during the "finalizing" of a KotoArtist called "has-no-albums" and as the name implies, informs our UI that there are no albums associated with an Artist. This enables us to dynamically swap either to the list view (if we received the "has-no-albums") or the flowbox view when there are Albums (notified via "album-added"). Since it is trivial enough to switch between them, it is quite likely that I can so some future refining to make it possible to choose one view as a persistent option, so if you prefer a list you could always use that.This last bit of work started to get done towards the end of the last stream for this month, so there is still some work to be done on enabling playback of the entire artist via an actual UX. We now generate an ephemeral (temporary) KotoPlaylist for the Artist, similar to what we end up doing for a KotoAlbum, we just have to build a UI to start listening to that playlist, like leveraging our KotoCoverArt and its click-to-play functionality.So yea, I did not get around to some of the Playlist settings I wanted to, or even that Solarized theme. However spending a month in the weeds of architecture is paying off and I am finally able to move on to sexier items.Goals for July:
Finish the implementation of the artist page in the "no albums" scenario.
Design and implement the user experience for audiobook listing, selection, and playback.
Implement our 10-band equalizer and playback speed controls.
Once that is done, I need to work on updating our logic for reporting Track durations and positions, not solely relying on GStreamer since its reporting has not always been reliable (especially noticeable with some of my FLAC and OGG files.). This updated logic will come in handy with the immediate task after that, which will be position saving.
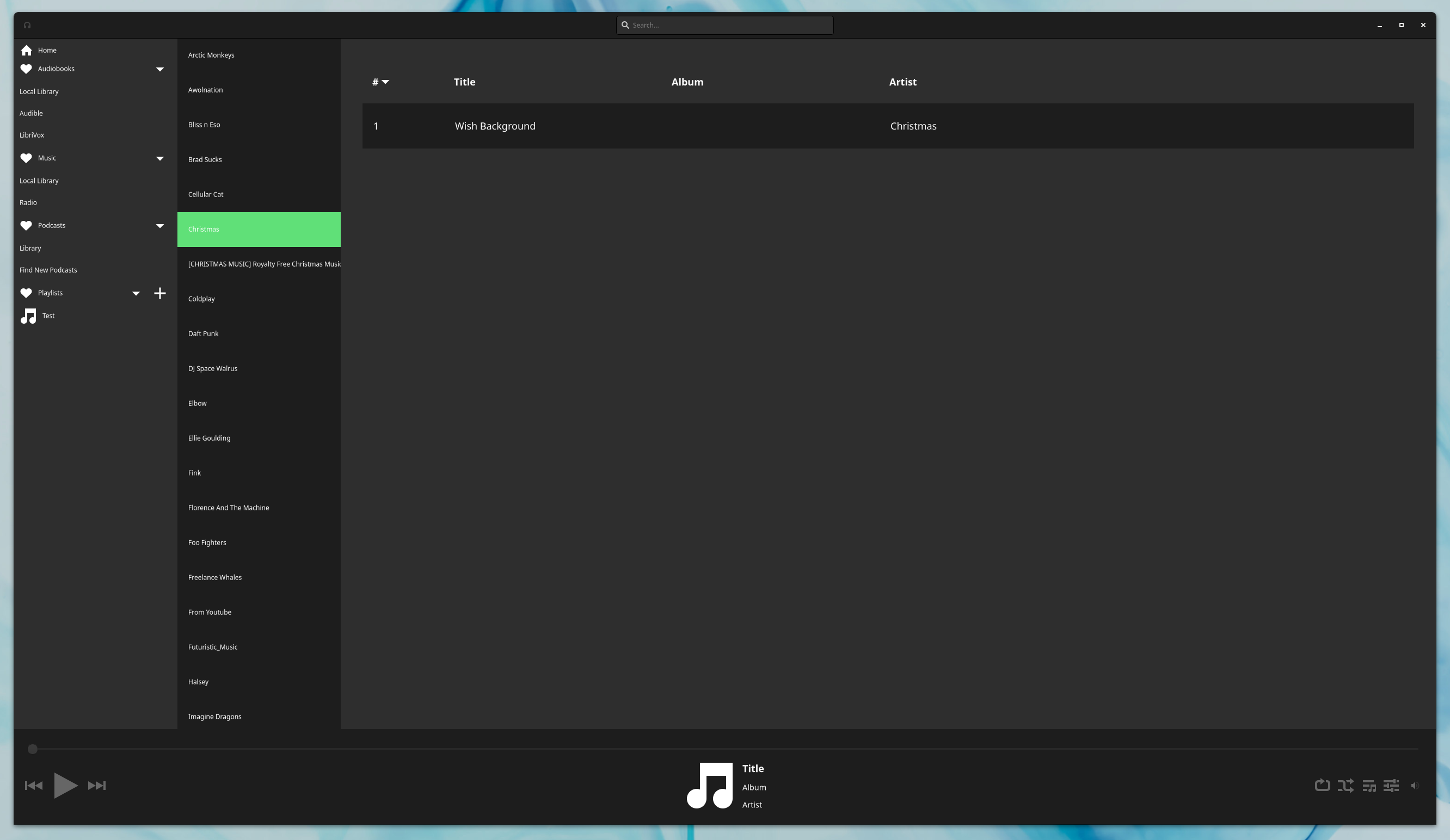
 This is made even more useful given we actually keep track of all KotoTracks within a KotoArtist in addition to any Albums. This is then leveraged as part of a new signal we emit during the "finalizing" of a KotoArtist called "has-no-albums" and as the name implies, informs our UI that there are no albums associated with an Artist. This enables us to dynamically swap either to the list view (if we received the "has-no-albums") or the flowbox view when there are Albums (notified via "album-added"). Since it is trivial enough to switch between them, it is quite likely that I can so some future refining to make it possible to choose one view as a persistent option, so if you prefer a list you could always use that.
This last bit of work started to get done towards the end of the last stream for this month, so there is still some work to be done on enabling playback of the entire artist via an actual UX. We now generate an ephemeral (temporary) KotoPlaylist for the Artist, similar to what we end up doing for a KotoAlbum, we just have to build a UI to start listening to that playlist, like leveraging our KotoCoverArt and its click-to-play functionality.
So yea, I did not get around to some of the Playlist settings I wanted to, or even that Solarized theme. However spending a month in the weeds of architecture is paying off and I am finally able to move on to sexier items.
Goals for July:
This is made even more useful given we actually keep track of all KotoTracks within a KotoArtist in addition to any Albums. This is then leveraged as part of a new signal we emit during the "finalizing" of a KotoArtist called "has-no-albums" and as the name implies, informs our UI that there are no albums associated with an Artist. This enables us to dynamically swap either to the list view (if we received the "has-no-albums") or the flowbox view when there are Albums (notified via "album-added"). Since it is trivial enough to switch between them, it is quite likely that I can so some future refining to make it possible to choose one view as a persistent option, so if you prefer a list you could always use that.
This last bit of work started to get done towards the end of the last stream for this month, so there is still some work to be done on enabling playback of the entire artist via an actual UX. We now generate an ephemeral (temporary) KotoPlaylist for the Artist, similar to what we end up doing for a KotoAlbum, we just have to build a UI to start listening to that playlist, like leveraging our KotoCoverArt and its click-to-play functionality.
So yea, I did not get around to some of the Playlist settings I wanted to, or even that Solarized theme. However spending a month in the weeds of architecture is paying off and I am finally able to move on to sexier items.
Goals for July: